LOGEST_q
Updated: 20 January 2017
Use the table-valued function LOGEST_q to calculate the exponential curve for a series of x- and y-values. The LOGEST_q function returns the statistics that describe the calculated solution, including the coefficients (m), the standard error of the coefficients (se), the t statistic for each coefficient (tstat) and the associated p-values (pval), the coefficient of determination (rsq), the adjusted r-square value (rsqa) and the modified r-square value (rsqm), the standard error of the y estimate (sey), the F-observed value (F), the residual degrees of freedom (df), the regression sum of squares (ss_reg), and the residual some of squares.
In the case where we have one column of x-values and a column of y-values, the LOGEST solution is:
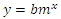
For purposes of multi-linear regression, where there are multiple columns of x-values (and still a single column of y-values), the formula for the solution is described by the following equation:
Where n is the number of x-columns and m0 is b. It's easy to see that by taking the natural logarithm, the exponential regression can be expressed as the linear regression of the natural logarithms:
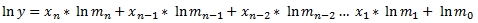
The function expects the input to be in row-column, or spreadsheet, format, rather than in third-normal form. Thus, the input into the function requires the specification of the column names for the x-values and the y-values, and the specification of a 1-based index identifying the column reference for the y-values. The column specifications and the table or view that contains the data are passed into the function as strings. The function dynamically creates SQL and the resultant table from the SQL is used as input into the OLS calculations.
LOGEST_q automatically detects collinearity and removes the right-most co-linear column resulting in a regression coefficient of 0 for that column.
Syntax
SELECT * FROM [wct].[LOGEST_q](
<@Matrix_RangeQuery, nvarchar(max),>
,<@Y_ColumnNumber, int,>
,<@Lconst, bit,>)
Arguments
@Matrix_RangeQuery
The SELECT statement, as a string, which, when executed, creates the resultant table of x- and y-values used in the calculation.
@y_ColumnNumber
the index into the resultant table identifying the column containing the y-values. The index value must be between 1 and n, where n is the number of columns in the resultant table created by @Matrix_RangeQuery. @y_ColumnNumber must be of the type int or of a type that implicitly converts to int.
@LConst
A logical value specifying whether to force the y-intercept value (m0) equal to zero. @LConst must be of the type bit or of a type that implicitly converts to bit.
Return Type
RETURNS TABLE (
[stat_name] [nvarchar](10) NULL,
[idx] [int] NULL,
[stat_val] [float] NULL,
[col_name] [nvarchar](128) NULL
)
Table Description
stat_name
Identifies the statistic being returned:
|
m
|
the estimated coefficient
|
|
se
|
the standard error of the estimated coefficient
|
|
tstat
|
the t statistic
|
|
pval
|
the p-value (t distribution) for the t statistic
|
|
rsq
|
the coefficient of determination (r2)
|
|
rsqa
|
adjusted r square
|
|
rsqm
|
multiple r square
|
|
sey
|
the standard error for the y estimate
|
|
f
|
the f-observed value
|
|
df
|
the residual degrees of freedom
|
|
ss_reg
|
the regression sum of squares
|
|
ss_resid
|
the residual sum of squares
|
idx
Identifies the subscript for the estimated coefficient, the standard error of the estimated coefficient, the t statistic, and the p-value. For example, the stat_name m with an idx of 0, specifies that the stat_val is for m0, or the y-intercept (which is b in y = mx + b). An idx of 1 for the same stat_name identifies m1.
The stat_name se with an idx of 0 identifies the standard error of the m0 coefficient (which is sometimes referred to as the standard error of b or seb).
idx values are only supplied for the m, se, tstat, and pval stat_names. All others will have an idx of NULL.
stat_val
the calculated value of the statistic.
col_name
the column name from the resultant table produced by the dynamic SQL. col_name values are produced only for the m, se, tstat, and pval statistics; all other stat_names have NULL for col_name.
Remarks
· If @Lconst is NULL then @LConst is set to 'True'.
· If @LConst is true than the number of rows must be greater than the number of columns.
· If @Lconst is false than the number of rows must be greater than or equal to the number of columns.
· If a y-value is < 0 then NULL will be returned.
· For simpler queries, you can try the LOGEST function.
Examples
Example #1
We put the x- and y-data into a temp table, #xy.
SELECT
*
INTO
#xy
FROM (VALUES
(508.78,0.34,3.95,1.75,4.41,49)
,(276.59,0.39,3.72,1.17,3.48,46.72)
,(82.07,0.41,2.35,1.64,3.98,13.03)
,(225.66,0.54,5.08,1.57,3.21,16.32)
,(176.03,0.35,3.31,1.19,3.73,34.16)
,(148.2,0.37,4.46,1.4,4.36,14.62)
,(357.56,0.38,5.51,1.63,3.74,27.97)
,(470.35,0.38,3.74,1.72,3.94,48.8)
,(308.7,0.48,4.76,1.55,3.37,25.84)
,(219.6,0.37,5.03,1.53,4.37,17.6)
)n(y,x0,x1,x2,x3,x4)
This is what the data look like.
To invoke the table-valued function LOGEST_q, we enter the following SQL.
SELECT
*
FROM
wct.LOGEST_q(
'SELECT y,x0,x1,x2,x3,x4 FROM #xy', --@Matrix_RangeQuery
1, --@Y_ColumnNumber
'True' --@Lconst
)
Essentially the function is dynamically creating a SQL statement to SELECT the column names from the #xy table. This means that we can actually simplify the second parameter, since we are selecting all the columns in this particular table, by entering the following:
SELECT
*
FROM
wct.LOGEST_q(
'SELECT * FROM #xy', --@Matrix_RangeQuery
1, --@Y_ColumnNumber
'True' --@Lconst
)
The following results are produced.
The results are returned in 3rd normal form. You can use standard SQL commands to re-format the results. For example, if you wanted to produce the the coefficients in a format similar to output of the Excel Data Analyis Regression Tool, you could use the following SQL[1].
;WITH mycte as (
SELECT *
FROM wct.LOGEST_q('SELECT * FROM #xy',1,1)p
)
SELECT
d.col_name
,d.m
,d.se
,d.tstat
,d.pval
,LOG(m)-wct.T_INV_2T(.05,m.stat_val)*se as [Lower Confidence Level]
,LOG(m)+wct.T_INV_2T(.05,m.stat_val)*se as [Upper Confidence Level]
FROM mycte p
PIVOT(MAX(stat_val) FOR stat_name in(m,se,tstat,pval))d
CROSS JOIN mycte m
WHERE stat_name = 'df'
AND d.col_name IS NOT NULL
This produces the follwing result.
Similarly, if you wanted to reformat the results to produce the equivalent of the ANOVA table from the Excel Data Analysis Regression tool, you could use the following SQL.
;WITH mycte as (
SELECT
df as [Residual df]
,Obs - df - 1 as [Regression df]
,ss_reg as [Regression SS]
,ss_resid as [Residual SS]
,F
FROM (
SELECT
stat_name
,stat_val
FROM
wct.LOGEST_q('SELECT * FROM #xy',1,1)
WHERE
stat_name in('ss_reg','ss_resid','F','df')
UNION
SELECT
'Obs'
,COUNT(*)
FROM
#xy)d
PIVOT(MAX(stat_val) FOR stat_name in(df,F,ss_reg,ss_resid,Obs))p
)
SELECT
'Regression'
,[Regression df] as DF
,[Regression SS] as SS
,[Regression SS]/[Regression df] as MS
,F
,wct.F_DIST_RT(F,[Regression df],[Residual df]) as [Significance F]
FROM
mycte
UNION ALL
SELECT
'Residual'
,[Residual df]
,[Residual SS]
,[Residual SS]/[Residual df] as [Residual MS]
,NULL
,NULL
FROM
mycte
UNION ALL
SELECT
'Total'
,[Regression df] + [Residual df]
,[Regression SS] + [Residual SS]
,NULL
,NULL
,NULL
FROM
mycte
This produces the following result.
Example #2
Using the same data as Example #1, if we wanted to calculate the coefficients without a y-intercept, we would modify function call to make the last parameter FALSE. This time, however, we will put the results into a temporary table, #L0, and reformat the results using the #L0 table.
SELECT
*
INTO
#L0
FROM
wct.LOGEST_q(
'SELECT * FROM #xy', --@Matrix_RangeQuery
1, --@Y_ColumnNumber
'True' --@Lconst
)
The #L0 table should contain the following data.
We can use the same technique as in Example #1 to reformat the coefficient statistics.
SELECT
d.col_name
,d.m
,d.se
,d.tstat
,d.pval
,LOG(m)-wct.T_INV_2T(.05,m.stat_val)*se as [Lower Confidence Level]
,LOG(m)+wct.T_INV_2T(.05,m.stat_val)*se as [Upper Confidence Level]
FROM
#L0 p
PIVOT(MAX(stat_val) FOR stat_name in(m,se,tstat,pval))d
CROSS JOIN #L0 m
WHERE
m.stat_name = 'df'
AND d.col_name IS NOT NULL
This produces the following result.
Note that even though we specified no intercept, an intercept row is still created with a regression coefficient of 1 (keeping the results consistent with the Excel Data Analysis Regression). It is simple enough to exclude this from the output (like R does) simply by adding another codition to the WHERE clause.
WHERE
m.stat_name = 'df'
AND d.col_name IS NOT NULL
AND d.col_name <> 'Intercept'
The following SQL can be used to reproduce the ANOVA table.
;WITH mycte as (
SELECT
df as [Residual df]
--,Obs - df - 1 as [Regression df]
,Obs - df as [Regression df]
,ss_reg as [Regression SS]
,ss_resid as [Residual SS]
,F
FROM (
SELECT
stat_name
,stat_val
FROM
#L0
WHERE
stat_name in('ss_reg','ss_resid','F','df')
UNION
SELECT
'Obs'
,COUNT(*)
FROM
#xy)d
PIVOT(MAX(stat_val) FOR stat_name in(df,F,ss_reg,ss_resid,Obs))p
)
SELECT
'Regression'
,[Regression df] as DF
,[Regression SS] as SS
,[Regression SS]/[Regression df] as MS
,F
,wct.F_DIST_RT(F,[Regression df],[Residual df]) as [Significance F]
FROM
mycte
UNION ALL
SELECT
'Residual'
,[Residual df]
,[Residual SS]
,[Residual SS]/[Residual df] as [Residual MS]
,NULL
,NULL
FROM
mycte
UNION ALL
SELECT
'Total'
,[Regression df] + [Residual df]
,[Regression SS] + [Residual SS]
,NULL
,NULL
,NULL
FROM
mycte
This produces the following result.
Note that the calculation of the regression degrees of freedom needs to be adjusted to reflect the absence on intercept. It also worthwhile noting that the calculation in this SQL produces a Significance F that agrees with R while Excel produces a different value (which seems to be caused be subtracting 1 from the residual degrees of freedom).
Example #3
Instead of just having a matrix of x- and y-values in our table, we are going to add a column, testid, which is a way of grouping x- and y-values together for purposes of doing the LOGEST calculation. This allows us to compute the ordinary least sqaures values for multiple sets of data in a single SELECT statement.
SELECT
*
INTO
#xy
FROM (VALUES
('Test1',3.93,57.91)
,('Test1',4.4,76.2)
,('Test1',3.33,20.78)
,('Test1',1.88,5.06)
,('Test1',3.68,32.53)
,('Test1',4.81,55.32)
,('Test1',4.27,57.83)
,('Test1',3.11,15.62)
,('Test1',3.81,22.93)
,('Test1',3.36,20.58)
,('Test2',12.56,5.19)
,('Test2',544.52,66.68)
,('Test2',955.35,96.94)
,('Test2',478.54,61.1)
,('Test2',565.07,68.28)
,('Test2',879.44,91.75)
,('Test2',988.58,99.19)
,('Test2',218.15,36.2)
,('Test2',523.75,64.97)
,('Test2',653.03,75.2)
,('Test3',10011.32,73.6)
,('Test3',14224.21,86.71)
,('Test3',12616.39,81.99)
,('Test3',731.51,21.7)
,('Test3',83.07,7.84)
,('Test3',7420.4,64)
,('Test3',3470.08,44.89)
,('Test3',4320.23,49.72)
,('Test3',257.08,13.31)
,('Test3',4083.32,48.43)
,('Test4',6.75,33.34)
,('Test4',10.66,95.33)
,('Test4',8.78,64.92)
,('Test4',8.46,57.19)
,('Test4',8.58,58.07)
,('Test4',8.13,64.62)
,('Test4',8.83,74.75)
,('Test4',8.56,59.43)
,('Test4',9.35,73.64)
,('Test4',7.4,46.11)
,('Test5',67.86,26.69)
,('Test5',198.1,66.08)
,('Test5',46.65,18.53)
,('Test5',246.06,79.92)
,('Test5',82.08,32.66)
,('Test5',306.95,97.34)
,('Test5',315.58,98.06)
,('Test5',231.01,76.41)
,('Test5',214.47,71.35)
,('Test5',155.25,54.05)
)n(testid,y,x0)
Let’s say we wanted to run LOGEST_q for the all the data where the testid is equal to Test3. We could simply enter the following statement.
SELECT
*
FROM
wct.LOGEST_q('SELECT y,x0 FROM #xy WHERE testid = ''Test3''',1,'True')
This produces the following result.
In the following SQL we return selected values for each test.
SELECT
p.testid
,p.rsq
,p.rsqa
,p.rsqm
,p.F
,p.df
,p.ss_reg
,p.ss_resid
FROM (
SELECT n.testid,k.stat_name,k.stat_val
FROM (SELECT DISTINCT testid FROM #xy)n
CROSS APPLY wct.LOGEST_q('SELECT y,x0 FROM #xy WHERE testid = ''' + n.testid + '''',1,'True') k
)d
PIVOT(SUM(stat_val) FOR stat_name IN(F,df,ss_reg,ss_resid,rsq,rsqm,rsqa))p
This produces the following result.
In this SQL we select the coefficient statistics for each of the tests.
SELECT
p.testid
,p.col_name
,p.m
,p.se
,p.tstat
,p.pval
FROM (
SELECT
n.testid
,k.stat_name
,k.idx
,k.col_name
,k.stat_val
FROM (
SELECT DISTINCT testid
FROM #xy)n
CROSS APPLY wct.LOGEST_q('SELECT y,x0 FROM #xy WHERE testid = ''' + n.testid + '''',1,'True') k
WHERE k.idx IS NOT NULL
)d
PIVOT(SUM(stat_val) FOR stat_name IN(m,se,tstat,pval))p
ORDER BY
testid
,idx
This produces the following result.
See Also
[1] The Excel Regression Tool does not directly support exponential regression. You would need to convert the y-values to ln(y). This means that the coefficients returned are the natural log of the coefficients.