CHITESTN2
Updated: 28 February 2011
Note: This documentation is for the SQL2008 (and later) version of this XLeratorDB function, it is not compatible with SQL Server 2005.
Click here for the SQL2005 version of the CHITESTN2 function
Use the aggregate function CHITESTN2 to calculate the Pearson chi-square test for independence on normalized tables. CHITESTN2 returns the value from the chi-square (χ2) distribution for the chi-sqaure statistic and the appropriate degrees of freedom. Calculate the chi-square statistic (χ2) directly using the CHISQN2 or the CHISQN2_q function.
The chi-square statistic is calculated by finding the difference between each observed and theoretical frequency for each possible outcome, squaring them, dividing each by the theoretical frequency, and taking the sum of the results. A second important part of determining the test statistic is to define the degrees of freedom of the test: this is essentially the number of squares errors involving the observed frequencies adjusted for the effect of using some of those observations to define the expected frequencies.
Given the test statistic and the degrees of freedom, the test value is returned by the regularized gamma function Q(a, x) where:
a is the degrees of freedom divided by 2
x is χ2 statistic divided by 2
CHITESTN2 requires the expected results as input to the function but automatically calculates the degrees of freedom.
The value of the test statistic is
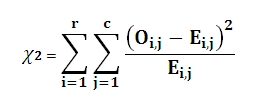
Where
r is the number of rows
c is the number of columns
O is the Observed result
E is the Expected result
Syntax
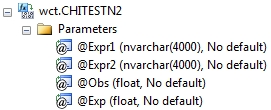
Arguments
@Expr1
the name or number of the rows.
@Expr2
the name or number of the columns.
@Obs
the observed value. @Obs is an expression of type float or of a type that can be implicitly converted to float.
@Exp
the expected value. @Exp is an expression of type float or of a type that can be implicitly converted to float.
Return Types
float
Remarks
· CHITESTN2 is designed for normalized tables.
· CHITESTN2 requires the expected values as input to the function. If you want to perform the chi-squared test without providing the expected values, use the CHITESTN function.
· CHITESTN2 = CHIDIST(χ2, df), where df = (r-1)(c-1), r>1, c>1.
· Use the CHISQN2 function to calculate the test statistic.
· CHITESTN2 is an aggregate function and follows the same conventions as all other aggregate functions in SQL Server.
· If you have previously used the CHITESTN2 scalar function, the CHITESTN2 aggregate has a different syntax. The CHITESTN2 scalar function is no longer available in XLeratorDB/statistics2008, though you can still use the scalar CHITESTN2 _q.
Examples
In this hypothetical situation, we want to determine if there is an association between population density and the preference for a sport from among baseball, football, and basketball. We will use the CHITESTN2 function to perform the chi-square test.
SELECT wct.CHITESTN2(
sport --@Expr1
,locale --@Expr2
,observed --@Obs
,expected --@Exp
) as CHITEST
FROM (VALUES
('Basketball', 'Rural', 28, 42.77),
('Basketball', 'Suburban', 35, 38.49),
('Basketball', 'Urban', 54, 35.74),
('Baseball', 'Rural', 60, 50.44),
('Baseball', 'Suburban', 43, 45.4),
('Baseball', 'Urban', 35, 42.16),
('Football', 'Rural', 52, 46.79),
('Football', 'Suburban', 48, 42.11),
('Football', 'Urban', 28, 39.1)
) n(sport, locale, observed, expected)
This produces the following result
CHITEST
----------------------
0.000162575660939674
(1 row(s) affected)
What if the expected results and the observed results are in 2 different tables? You could try something likes this.
SELECT * INTO #o
FROM (VALUES
('Basketball', 'Rural', 28),
('Basketball', 'Suburban', 35),
('Basketball', 'Urban', 54),
('Baseball', 'Rural', 60),
('Baseball', 'Suburban', 43),
('Baseball', 'Urban', 35),
('Football', 'Rural', 52),
('Football', 'Suburban', 48),
('Football', 'Urban', 28)
) o(sport, locale, result)
SELECT * INTO #e
FROM (VALUES
('Basketball', 'Rural', 42.77),
('Basketball', 'Suburban', 38.49),
('Basketball', 'Urban', 35.74),
('Baseball', 'Rural', 50.44),
('Baseball', 'Suburban', 45.4),
('Baseball', 'Urban', 42.16),
('Football', 'Rural', 46.79),
('Football', 'Suburban', 42.11),
('Football', 'Urban', 39.1)
)e(sport, locale, result)
SELECT wct.CHITESTN2(#o.sport, #o.locale, #o.result, #e.result) as CHITEST
FROM #o, #e
WHERE #o.sport = #e.sport
AND #o.locale = #e.locale
DROP TABLE #o
DROP TABLE #e
This produces the following result.
CHITEST
----------------------
0.000162575660939674
(1 row(s) affected)
The previous example relied on the temporary tables. If you want to avoid using temporary tables, you could use the following SQL which uses a CTE and a derived table.
;with obs as (
SELECT *
FROM (VALUES
('Basketball', 'Rural', 28),
('Basketball', 'Suburban', 35),
('Basketball', 'Urban', 54),
('Baseball', 'Rural', 60),
('Baseball', 'Suburban', 43),
('Baseball', 'Urban', 35),
('Football', 'Rural', 52),
('Football', 'Suburban', 48),
('Football', 'Urban', 28)
) o(sport, locale, result)
) SELECT wct.CHITESTN2(obs.sport, obs.locale, obs.result, e.result) as CHITEST
FROM (VALUES
('Basketball', 'Rural', 42.77),
('Basketball', 'Suburban', 38.49),
('Basketball', 'Urban', 35.74),
('Baseball', 'Rural', 50.44),
('Baseball', 'Suburban', 45.4),
('Baseball', 'Urban', 42.16),
('Football', 'Rural', 46.79),
('Football', 'Suburban', 42.11),
('Football', 'Urban', 39.1)
)e(sport, locale, result), obs
WHERE obs.sport = e.sport
AND obs.locale = e.locale
This produces the following result.
CHITEST
----------------------
0.000162575660939674
(1 row(s) affected)
You could also use 2 derived table, using the CROSS JOIN capability, but we would recommend not doing this as it will create the Cartesian product of the observed results and the expected results.
SELECT wct.CHITESTN2(o_sport, o_locale, o_result, e_result) as CHITEST
FROM (VALUES
('Basketball', 'Rural', 28),
('Basketball', 'Suburban', 35),
('Basketball', 'Urban', 54),
('Baseball', 'Rural', 60),
('Baseball', 'Suburban', 43),
('Baseball', 'Urban', 35),
('Football', 'Rural', 52),
('Football', 'Suburban', 48),
('Football', 'Urban', 28)
) o(o_sport, o_locale, o_result)
CROSS JOIN
(VALUES
('Basketball', 'Rural', 42.77),
('Basketball', 'Suburban', 38.49),
('Basketball', 'Urban', 35.74),
('Baseball', 'Rural', 50.44),
('Baseball', 'Suburban', 45.4),
('Baseball', 'Urban', 42.16),
('Football', 'Rural', 46.79),
('Football', 'Suburban', 42.11),
('Football', 'Urban', 39.1)
) e(e_sport, e_locale, e_result)
WHERE e_sport = o_sport
AND e_locale = o_locale
This produces the following result.
CHITEST
----------------------
0.000162575660939674
(1 row(s) affected)
What if the expected and observed results are stored in spreadsheet format? We could try the following SQL.
SELECT wct.CHITESTN2(n.sport, o_locale, o_result, e_result) as CHITEST
FROM (VALUES
('Basketball', 28, 35, 54, 42.77, 38.49, 35.74),
('Baseball', 60, 43, 35, 50.44, 45.4, 42.16),
('Football', 52, 48, 28, 46.79, 42.11, 39.1)
) n(sport, o_rural, o_suburban, o_urban, e_rural, e_suburban, e_urban)
CROSS APPLY(VALUES
('rural', o_rural),
('suburban', o_suburban),
('urban',o_urban)
) o(o_locale, o_result)
CROSS APPLY(VALUES
('rural', e_rural),
('suburban', e_suburban),
('urban',e_urban)
) e(e_locale, e_result)
WHERE o_locale = e_locale
This produces the following result.
CHITEST
----------------------
0.000162575660939674
(1 row(s) affected)
In this example, the data are compiled by region in spreadsheet format. We can calculate the chi square test for each region in the following SQL.
SELECT n.region
,wct.CHITESTN(n.sport, o_locale, o_result) as CHITEST
FROM (VALUES
('Midwest','Baseball',37,33,40,37.83,36.43,35.73),
('Midwest','Basketball',32,39,33,35.77,34.45,33.78),
('Midwest','Football',39,32,29,34.39,33.12,32.48),
('Northeast','Baseball',27,34,40,32.81,31.84,36.03),
('Northeast','Basketball',44,30,36,35.73,34.68,39.24),
('Northeast','Football',31,35,36,33.13,32.16,36.38),
('Southeast','Baseball',26,34,34,26.64,27.54,24.55),
('Southeast','Basketball',34,33,27,26.64,27.54,24.55),
('Southeast','Football',29,25,21,21.26,21.97,19.59),
('Southwest','Baseball',26,35,44,27.75,30.1,32.1),
('Southwest','Basketball',26,30,30,22.73,24.65,26.29),
('Southwest','Football',31,25,22,20.62,22.36,23.85),
('West','Baseball',39,37,38,43.2,37.39,39.57),
('West','Basketball',36,29,39,39.41,34.11,36.1),
('West','Football',44,37,32,42.82,37.07,39.23)
) n(region, sport, o_urban, o_rural, o_suburban, e_urban, e_rural, e_suburban)
CROSS APPLY(VALUES
('rural', o_rural),
('suburban', o_suburban),
('urban',o_urban)
) o(o_locale, o_result)
CROSS APPLY(VALUES
('rural', e_rural),
('suburban', e_suburban),
('urban',e_urban)
) e(e_locale, e_result)
WHERE o_locale = e_locale
GROUP BY n.region
This produces the following result.
region CHITEST
--------- ----------------------
Midwest 0.575117058900146
Northeast 0.308608930077901
Southeast 0.557693584099196
Southwest 0.218870732592999
West 0.674592124462302
(5 row(s) affected)
Since the data are compiled in spreadsheet format, we could have also used the scalar function, CHITEST2. The CHITEST2 scalar function does not have addressability to a derived table or a CTE, so the data need to be contained in a table or a temporary table. Here’s the same data put into a temporary table and select using the CHISQ2 function.
SELECT *
INTO #c
FROM (VALUES
('Midwest','Baseball',37,33,40,37.83,36.43,35.73),
('Midwest','Basketball',32,39,33,35.77,34.45,33.78),
('Midwest','Football',39,32,29,34.39,33.12,32.48),
('Northeast','Baseball',27,34,40,32.81,31.84,36.03),
('Northeast','Basketball',44,30,36,35.73,34.68,39.24),
('Northeast','Football',31,35,36,33.13,32.16,36.38),
('Southeast','Baseball',26,34,34,26.64,27.54,24.55),
('Southeast','Basketball',34,33,27,26.64,27.54,24.55),
('Southeast','Football',29,25,21,21.26,21.97,19.59),
('Southwest','Baseball',26,35,44,27.75,30.1,32.1),
('Southwest','Basketball',26,30,30,22.73,24.65,26.29),
('Southwest','Football',31,25,22,20.62,22.36,23.85),
('West','Baseball',39,37,38,43.2,37.39,39.57),
('West','Basketball',36,29,39,39.41,34.11,36.1),
('West','Football',44,37,32,42.82,37.07,39.23)
) n(region, sport, o_urban, o_rural, o_suburban, e_urban, e_rural, e_suburban)
SELECT region
,wct.CHITEST2('#c'
,'o_urban, o_rural, o_suburban'
,'region'
,region
,'#c'
,'e_urban, e_rural, e_suburban'
,'region'
,region) as CHITEST
FROM #c
GROUP BY region
DROP TABLE #c
This produces the following result.
region CHITEST
--------- ----------------------
Midwest 0.575300646898332
Northeast 0.306513399471444
Southeast 0.0183771257212259
Southwest 0.0105421314688606
West 0.535761107422311
(5 row(s) affected)